|
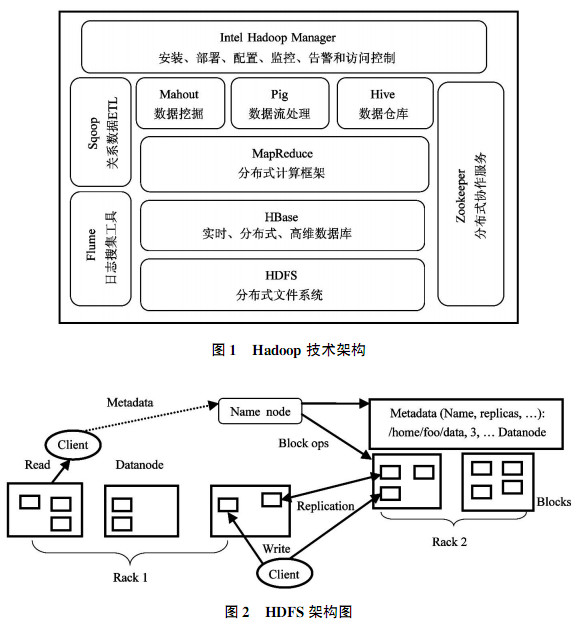
1国内外大数据软件应用研究 1.1Hadoop 2004年,Google发布了关于分布式计算框架MapReduce的大规模数据并行处理技术的论文。Doug Cutting根据Google提出的设计思想,用Java设计出一套与Nutch分布式文件系统(Nutch Distributed File System,NDFS)相结合且支持Nutch搜索引擎的并行处理软件系统。该系统从Nutch中分离出来并被命名为“Hadoop”。Hadoop作为Apache最大的一个开源项目,是以Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)和MapReduce为核心的大数据处理平台和生态系统,该系统包含了HBase、Hive、Zookeeper等一系列相关子项目。Hadoop的技术架构如图1所示。 分布式文件系统HDSF作为Hadoop最核心的设计之一,为Hadoop分布式计算框架提供高性能、高可靠、高可扩展的存储服务。HDFS是一个典型的主从架构,其主要包含一个名字节点NameNode(主节点)和多个数据节点DataNode(从节点),并提供应用程序访问接口。NameNode是整个文件系统的管理节点,负责文件系统名字空间的管理与维护,同时负责客户端文件操作的控制以及具体存储任务的管理和分配;DataNode提供真实文件数据的存储服务,启动DataNode线程同时向NameNode汇报数据块的情况,系统架构如图2所示。
在分布式文件系统HDFS中,可能会有多个机架Rack,每个机架上管理多个DataNode。为防灾容错,一个数据块Block(数据块大小默认64M)的三个副本通常会保存到两个或两个以上的机架中,例如,一个放在机架Rack1中的DataNode1中,一个放在不同机架Rack2的DataNode1中,另一个则放在Rack1的DataNode2中,此分配方法确保系统中的机架掉电或者机架的交换机发生错误时,系统的运行不受到影响,以及数据不会遗失。DataNode通过每3秒向NameNode发送心跳来保持通信的,一旦心跳停止,将会认为DataNode错误,NameNode会将其上的数据块复制到其他的DataNode上。
分布式计算框架MapReduce作为Hadoop另一最核心的设计,是一个针对大规模群组中的海量数据处理的分布式编程模型。MapReduce实现两个功能。其一,Map把一个函数应用于集合中的所有成员,返回一个基于这个处理的结果集。其二,Reduce把通过多个线程、进程或者独立系统并行执行处理的结果集进行分类和归纳。Map和Reduce两个函数可并行运行。MapReduce程序的第一步叫做mapping,将数据元素作为Mapper函数的输入数据,每次一个,Mapper把每次mapping得到的结果单独传输到输出数据元素里。Mapper模型如图3所示。Mapping对输入数据列表中的每一个元素应用一个函数创建一个新的输出数据列表,即键值对。Reducing具有聚集数据功能,Reducer函数接收来自输入列表的迭代器,将数据聚集在一起,返回一个值。Reducer模型如图4所示。 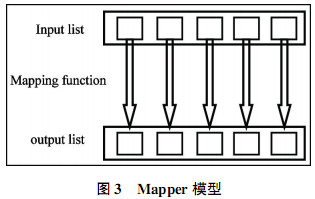 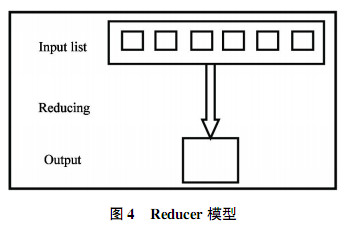
Reducing一般用来生成汇总数据,将大规模的数据转变成更小的总结数据。数据通过Reducer的分析处理,最终将结果输出。通常作业的输入和输出都存储在文件系统中,MapReduce框架和分布式文件系统运行在一组相同的节点上。MapReduce框架可在已经存好数据的节点上高效运行,使整个集群的网络带宽高效利用。Hadoop具有高可靠性,高扩展性,高容错性,高效性等特点。这些特点符合农业数据处理的要求,可将Hadoop用于农业数据的处理中,分布式文件系统HDFS可存储农业数据,结合MapReduce将数据处理,输出处理结果,为用户提供技术支持。Hadoop将海量农业数据分割于多个节点,由每一个节点并行计算,将得出的结果归并到输出。运用迭代算法的思想,构建树状结构的分布式计算图,并行、串行结合的计算在分布式集群的资源下高效处理。Hadoop数据处理方法相对传统数据分析方法不仅快速,而且在处理农业数据时将多元化的农业数据融合分析,分析出数据的相关性。
Hadoop在农业数据的分析处理中具有很多的优势,但是仍存在不足。第一,Hadoop的高可用性。HDFS与MapReduce都采用单主机(master)的处理方式,集群中的其他机器都与中心机器进行通信,一旦中心机器损坏,集群停止工作,可用性降低,即单点失败。目前,针对这个已研究出初步解决方案,即对master节点进行镜像备份,一旦master出现错误,即刻换上镜像备份的机器,提高可用性,但这是基于内置的解决方案,不能从根本上解决问题。第二,Hadoop不适用迭代次数过多的算法(比如:矩阵的奇异值分解)。MapReduce每次迭代都需将数据往文件里面读写一遍,浪费大量的时间。第三,不能实现实时性,不能响应毫秒级响应,事物型查询用时较长。农业数据中含有海量的非结构数据,Hadoop处理起来十分的复杂,处理速度缓慢,一旦发生单点失败,机器需重启重新处理,会导致处理时间过长。而且Hadoop不能实现实时性,导致很多的数据不能及时处理,对于需要实时分析数据输出结果以便作出调整的指标没有作用。
相对于Hadoop,Storm主要采用全内存计算,Storm接收到数据就实时处理并分发,因而Storm处理速度快,被广泛应用于实时日志处理、实时统计、实时风控、实时推荐等场景中。
|