|
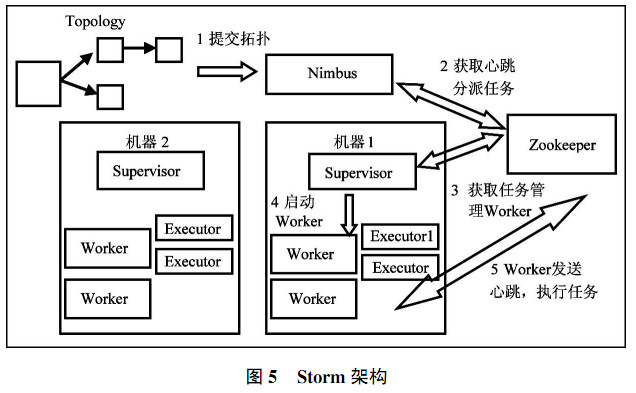
1.2 Storm 2011年,Hadoop凭借着高吞吐,方便处理海量数据的优势奠定其在大数据的主要地位。Hadoop专注于大规模数据存储和处理,但是Hadoop的MapReduce延迟大,响应缓慢,运维复杂,不适用于实时大数据方面。针对业务场景中对秒级别甚至毫秒级别响应的需求,Twitter公司推出开源分布式、容错的实时流计算系统Storm,解决了大规模数据实时处理的问题。Storm是一个分布式的、容错的实时计算系统,适用于计算机集群中编写与扩展复杂的实时计算。 Storm集群由一个主节点和多个工作节点组成,Storm架构图如图5所示。主节点运行Nimbus守护进程,用于分配代码、布置任务及故障检测。每个工作节点运行Supervisor守护进程,开始并终止工作进程。ZooKeeper用于管理集群中的不同组件,协调Nimbus和Supervisor两者的工作,topology是由计算节点组成的图,节点包括处理的逻辑。 Storm的工作过程是Nimbus针对该拓扑建立本地的目录,根据topology的配置计算作业、分配作业,在zookeeper上建立任务节点assignments存储作业task和supervisor机器节点中worker的对应关系,以及创建作业节点taskbeats来监控作业的心跳,启动topology。Supervisor从zookeeper上获取分配的作业task,启动多个worker,worker生成作业task,一个作业task一个线程;根据topology信息初始化建立作业task之间的连接;作业和作业之间通过可嵌入的网络通讯库管理,最后整个拓扑运行起来。 Storm有很多的优势。第一,简单的编程模型。Storm降低实时处理的复杂性。第二,可以使用各种编程语言。Storm默认支持Clojure、Java、Ruby和Python。通过实现一个简单的Storm通信协议,可增加对其他语言的支持。第三,容错性。Storm管理工作进程和节点的故障。第四,水平扩展。计算在多个线程、进程和服务器之间并行进行。第五,可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。第六,快速。系统的设计使用网络通讯库作为其底层消息队列,保证消息能得到快速的处理。第七,本地模式。Storm“本地模式”可在处理过程中完全模拟Storm集群,可快速进行开发和单元测试。 Storm也存在一些亟待解决的问题。第一,目前的开源版本中只是单节点Nimbus,故障只能自动重启,可考虑实现一个双Nimbus的布局。第二,Clojure是一个在Java虚拟机平台运行的动态函数式编程语言,优势在于流程计算,Storm的部分核心内容由Clojure编写,性能提高的同时也提升维护成本。因此,Storm适合用于需要实时分析的农业数据,如农业大棚中的温度、湿度监测等,可以迅速地分析出结果。
|